목차
이번 포스트에서는 파이참(Pycharm)에 mecab을 설치하고 사용하는 방법에 대해서 다뤄보겠습니다.
1. 설치
Mecab은 일본에서 개발된 형태소 분석기입니다. 한국의 문법 체계가 일본과 유사하기 때문에 은전한닢 프로젝트를 통해 한국어에 맞게 개발되었고, 현재 한국어 자연어 처리를 위해 많이 사용되고 있습니다.
설치 방법은 아래와 같습니다.
(1) 먼저, C 드라이브에 mecab 이라는 폴더를 만들어줍니다. ('C:\mecab')
(2) https://github.com/Pusnow/mecab-ko-msvc/releases/tag/release-0.9.2-msvc-3 링크에서 본인의 윈도우 비트에 맞는 zip 파일을 다운 받고, C:\mecab 아래에서 압축을 풀어줍니다. 이때 모든 파일들이 C:\mecab 바로 밑에 있도록 해야합니다. 이 파일은 mecab 프로그램과 관련된 파일입니다.
(3) https://github.com/Pusnow/mecab-ko-dic-msvc/releases/tag/mecab-ko-dic-2.1.1-20180720-msvc-2 링크에서 zip 파일을 다운 받고, 마찬가지로 C:\mecab 아래에서 압축을 풀어줘서 모든 파일들이 C:\mecab 바로 밑에 있도록 합니다. 이 파일은 한국어 사전과 관련된 파일입니다.
(4) https://github.com/Pusnow/mecab-python-msvc/releases 링크에서 본인의 윈도우 비트와 파이썬 버전에 맞는 whl 파일을 다운 받아줍니다. 저는 64비트에 파이썬 3.10 버전을 사용하고 있기 때문에 'mecab_python-0.996_ko_0.9.2_msvc-cp310-cp310-win_amd64.whl' 파일을 다운 받았습니다. 그리고 다운 받은 파일을 가상환경의 Lib/site-packages 아래로 옮겨줍니다.
(5) 파이참(Pycharm)을 오픈하고, 가상 환경을 만들어줍니다.
(6) 이제 파이참의 터미널에서 pip install로 패키지를 설치합니다.
pip install venv/Lib/site-packages/mecab_python-0.996_ko_0.9.2_msvc-cp310-cp310-win_amd64.whl
(7) 아래의 코드를 실행해서 mecab이 잘 설치되었는지 확인해봅니다. 출력이 아래와 같이 나온다면, 설치가 잘 된 것입니다.
import MeCab
m = MeCab.Tagger()
a = m.parse("새침하게 흐린 품이 눈이 올 듯하더니 눈은 아니 오고 얼다가 만 비가 추적추적 내리었다. 이날이야말로 동소문 안에서 인력거꾼 노릇을 하는 김 첨지에게는 오래간만에도 닥친 운수 좋은 날이었다.")
print(a)
## 새침 NNG,*,T,새침,*,*,*,*
## 하 XSV,*,F,하,*,*,*,*
## 게 EC,*,F,게,*,*,*,*
## 흐린 VV+ETM,*,T,흐린,Inflect,VV,ETM,흐리/VV/*+ᆫ/ETM/*
(8) MeCab을 바로 사용해도 좋지만, konlpy 패키지를 통해서 사용하면 더 편합니다.
예를 들어, 아래의 코드를 사용하면 한국어 텍스트의 명사만 추출할 수 있습니다.
from konlpy.tag import Mecab
mecab = Mecab(dicpath=r"C:\mecab\mecab-ko-dic")
mecab.nouns("새침하게 흐린 품이 눈이 올 듯하더니 눈은 아니 오고 얼다가 만 비가 추적추적 내리었다. 이날이야말로 동소문 안에서 인력거꾼 노릇을 하는 김 첨지에게는 오래간만에도 닥친 운수 좋은 날이었다.")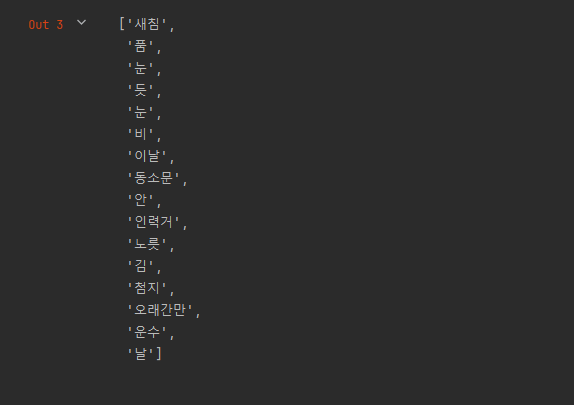
2. 사용자 사전 추가하기
다음의 코드를 통해 나관중의 삼국지의 문장 하나에서 명사를 추출해봅시다.
from konlpy.tag import Mecab
mecab = Mecab(dicpath=r"C:\mecab\mecab-ko-dic")
mecab.nouns('그때는 북소리 한번으로 손권을 사로잡을 수 있을 것입니다')
저는 '손권'이라는 명사가 추출되기를 바랐지만, '손' 이라는 단어가 추출되었습니다. 이는 '손권'이 사전에 등록되어 있지 않기 때문입니다. 이제 '손권'이라는 단어를 사용자 사전에 추가해봅시다. 이를 위해서 C:\mecab\user-dic 폴더의 nnp.csv 파일을 수정해줘야 합니다. 먼저 파일을 읽어봅시다.
with open("C:/mecab/user-dic/nnp.csv", 'r', encoding='utf-8') as f:
txt_data = f.readlines()
txt_data
그러면 이미 파일에 '대우'와 '구글'이라는 단어가 아래와 같은 형식으로 등록되어 있는 것을 확인 할 수 있습니다. 형식의 의미는 다음과 같습니다:
표층형, 0, 0, 0, 품사 태그, 의미 부류, 종성 유무, 읽기, 타입, 첫번째 품사, 마지막 품사, 표현

이제 '손권' 이라는 고유명사를 등록해봅시다. 고유명사니까 NNP를 설정하고 종성이 있기 때문에 T를 설정하면 됩니다.
txt_data.append('손권,,,,NNP,*,T,손권,*,*,*,*,*\n')
with open("C:/mecab/user-dic/nnp.csv", 'w', encoding='utf-8') as f:
for line in txt_data:
f.write(line)파일을 수정했으면, Windows Powershell을 관리자 권한으로 실행하고, 위치를 C:\mecab 로 옮겨줍니다. 그리고 아래와 같이 .\tools\add-userdic-win.ps1 파일을 실행해줘서 사용자 정의 사전을 등록하면 됩니다. 만약 주피터 노트북을 통해서 mecab을 사용하고 있었다면, 주피터 커널을 종료한 뒤에 .\tools\add-userdic-win.ps1 파일을 실행해야 합니다.
이제 다시 다시 한번 삼국지의 문장을 시험해봅시다.
그러면 결과가 달라지지 않는 것을 확인할 수 있습니다. 왜일까요?
이는 '손권'이라는 단어가 사전에는 등록되었지만, 기존에 사전에 등록된 단어에 비해 우선 순위가 낮기 때문입니다. 따라서 단어의 우선 순위를 조정해줘야 합니다.
from konlpy.tag import Mecab
mecab = Mecab(dicpath=r"C:\mecab\mecab-ko-dic")
mecab.nouns('그때는 북소리 한번으로 손권을 사로잡을 수 있을 것입니다')
3. 단어 우선 순위 조정
단어의 우선 순위를 조정하기 위해서는 C:\mecab\mecab-ko-dic 폴더의 user-nnp.csv 파일을 수정해줘야 합니다. 아래의 코드를 통해 파일을 읽어보면 다음과 같습니다. 우리가 처음에 사전을 등록했을 때와 다르게 첫 열 뒤에 3개의 숫자가 생긴 것을 확인할 수 있습니다. 이 숫자중 마지막 숫자, 즉 4번째 열이 바로 각 단어의 우선순위 입니다.
with open("C:/mecab/mecab-ko-dic/user-nnp.csv", 'r', encoding='utf-8') as f:
user_dic = f.readlines()
user_dic
그럼 이제 아래의 코드를 통해 사용자 정의 사전의 모든 단어의 우선 순위를 0으로 만들겠습니다.
with open("C:/mecab/mecab-ko-dic/user-nnp.csv", 'w', encoding='utf-8') as f:
for line in user_dic:
splt_txt = line.split(",")
splt_txt[3] = '0'
new_order = ",".join(splt_txt)
f.write(new_order)아래를 보면 우선순위가 잘 바뀐 것을 확인할 수 있습니다.
with open("C:/mecab/mecab-ko-dic/user-nnp.csv", 'r', encoding='utf-8') as f:
txt_data = f.readlines()
txt_data
우선 순위를 수정했으면, Windows Powershell을 관리자 권한으로 실행하고, 위치를 C:\mecab 로 옮겨줍니다. 그리고 아래와 같이 .\tools\compile-win.ps1 파일을 실행해줘서 사용자 정의 사전을 컴파일 하면 됩니다. 만약 주피터 노트북을 통해서 mecab을 사용하고 있었다면, 주피터 커널을 종료한 뒤에 .\tools\compile-win.ps1 파일을 실행해야 합니다.
이제 우리를 골치 아프게 했던 삼국지의 문장을 확인해봅시다.
결과를 보면 이제 '손권' 이라는 단어가 완벽하게 추출되는 것을 확인할 수 있습니다.
from konlpy.tag import Mecab
mecab = Mecab(dicpath=r"C:\mecab\mecab-ko-dic")
mecab.nouns('그때는 북소리 한번으로 손권을 사로잡을 수 있을 것입니다')